Chrome Extension Development
Do you like JavaScript? Have you been looking for a reaon or an idea to learn and start using HTML5? Google Chrome extesions are a great way to get into HTML5 and all its new APIs with bite sized applications.
Anatomy of a Chrome Extension
A Chrome extesion is nothing more than a tiny website that runs hosted inside Chrome. Like any website, it consists of regular web components. Grossly simplifying it is just a directory full of files, such as JavaScript, CSS, images, HTML5, and anything else you usually add to a web page.
Because it runs inside the browser, you have access to things like browser events, browsing history, and open tabs.
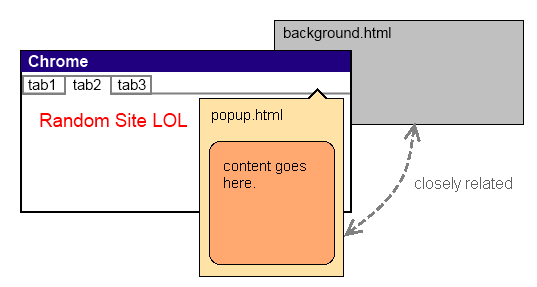
Essentially, your extension gets loaded as an HTML page called background.html where you can put any common/global functions and variables. This page is never visible and even if you don't provide a background.html in your extension, Chrome will load an empty one for you. All other pages in your extension can access the background page's functions.
Here's a diagram of a common scenario.
Today's Brew
Our sample extension will be something simple but that at the same time will let us explore interesting aspects of extensions development, namely local storage and cross-domain requests.
The sample is also a hat tip to the valuable work Chris Alcock does with his The Morning Brew, collecting some of the best links for all of us.
What we will do here is create an extension that will show us his latests links at the click of a button.
Introduce yourself
The extension needs to inform Chrome a few details about itself, such as name, default icons, along with any permissions it requests to access privileged browser features. This is done through the manifest file, which is just a JSON document. Here's our manifest file, aptly named manifest.json.
{
"name": "Today's Brew",
"version": "1.0",
"description": "Latest links from The Morning Brew.",
"icons": {
"48": "icon48.png",
"128": "icon128.png"
},
"browser_action": {
"default_icon": "icon.png",
"default_popup": "popup.html"
},
"permissions": [
"http://feeds.feedburner.com/",
"tabs"
]
}
What you can do
Extensions can perform several different jobs, like showing notifications, providing new themes, changing some of the default Chrome pages, etc. One other thing they can do are the browser actions, which basically means adding a button to the toolbar that acts independent of what page is being shown, as if it were just another browser feature.
If you look at our manifest file you'll notice we declared a browser_action, with its icon and the page it opens wen clicked.
Our extension does not have a custom background page, we will just rely on the default one Chrome will give us and put all of our logic in the popup page that we will open.
What you need to do that
Here's how our extension will look like when we're done.
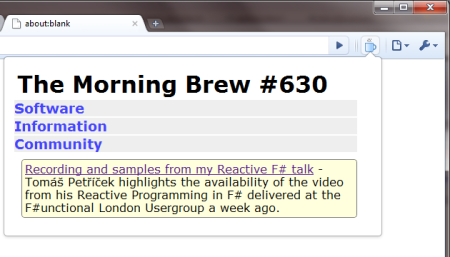
In our extension, other than manipulating our own extension's HTML dynamically (which doesn't require any special permissions) we will need to fetch the RSS feed from Feedburner and eventually open new tabs as the user clicks on the links.
That's what you can see in the permissions section of the manifest file above.
Getting down to business
To create our extension we start by creating an empty directory and adding our manifest.json file and all the icon image files that we mentioned in that manifest file.
Then we create our popup.html file, which will be pretty empty and will be populated with the content we will retrieve from the RSS feed. Here's that file.
<script type="text/javascript" src="jquery.js"></script> <script type="text/javascript" src="popup.js"></script> <div id="main"> <h1></h1> <div id="content"> </div> </div>
As you can see, we will be using jQuery so we should also add that file to our directory. We will leave all the beautification of the popup in the popup.css file, which I won't bother showing here; you can download it along with the rest of the code at the end of this article.
The other file referenced by the HTML is popup.js. That's where all the action happens.
$(document).ready(function(){
SERGIOPEREIRA.samples.todaysBrew.init();
});
var SERGIOPEREIRA = {
samples: {
todaysBrew: {
state: { },
feedUrl: 'http://feeds.feedburner.com/ReflectivePerspective?format=xml',
todaysUrl: '',
maxAgeHours: 12, // keep it for 12 hours
init: function(){
$('#content h3').live('click', function(){
$('#content ul:visible').slideUp();
$(this).next().slideToggle();
});
$('#content li a').live('click', function(){
$('#content ul:visible').slideUp();
chrome.tabs.create({url: this.href});
});
$('h1').click(function(){
chrome.tabs.create({url: SERGIOPEREIRA.samples.todaysBrew.todaysUrl});
});
if(typeof chrome != 'undefined') {
this.state = localStorage.getItem('latestBrew');
if(this.state){
var now = new Date();
var minTimestamp = new Date();
minTimestamp.setHours(minTimestamp.getHours() - this.maxAgeHours);
minTimestamp = minTimestamp.toJSON();
if(this.state.timestamp > minTimestamp) {
this.renderLatest(this.state.latestData);
return;
}
}
this.refresh();
}
},
refresh: function(){
console.log('will get feed data...');
$.get(this.feedUrl, function(xml, status, xhr){
SERGIOPEREIRA.samples.todaysBrew.update(xml);
});
},
update: function(feedXml) {
var latest = this.getFirstItem(feedXml);
this.state = { };
this.state.latestData = latest;
this.state.timestamp = new Date();
localStorage['latestBrew'] = JSON.stringify(this.state);
this.renderLatest(latest);
},
renderLatest: function(latest){
$('#main>h1').text(latest.title);
$('#content').html(latest.content);
this.todaysUrl = latest.url;
},
getFirstItem: function(feedXml){
var items = feedXml.evaluate("//channel/item", feedXml,
null, XPathResult.ANY_TYPE, null);
var item = items.iterateNext();
if (item) {
return this.createItem(item);
}
},
createItem: function(postXml) {
return {
title: this.readElementText(postXml, 'title'),
url: this.readElementText(postXml, 'feedburner:origLink'),
content: this.readElementText(postXml, 'content:encoded')
};
},
mapElements: function(contextElement, path, map){
var result = [ ];
var items = contextElement.ownerDocument.evaluate(path, contextElement,
this.namespaceResolver, XPathResult.ANY_TYPE, null);
var item = items.iterateNext();
var i = 0;
while (item) {
result.push( map(item, i++) );
item = items.iterateNext();
}
return result;
},
readElementText: function(contextElement, path){
var results = contextElement.ownerDocument.evaluate(path, contextElement,
this.namespaceResolver, XPathResult.ANY_TYPE, null);
var first = results.iterateNext();
if (first) {
return first.textContent;
}
},
namespaceResolver: function(prefix) {
if(prefix == 'content') {
return 'http://purl.org/rss/1.0/modules/content/';
}
if(prefix == 'feedburner') {
return 'http://rssnamespace.org/feedburner/ext/1.0';
}
}
}
}
};
Wow, that's a lot of JavaScript at once, right? Hopefully you'll notice that most of it is just to parse the RSS xml.
Only a few parts of this code deserve commentary. The refresh method (line 45) is the one
that retrieves the RSS data. It uses the jQuery.get method to do so. Once the data arrives, it will
invoke update, which will use the parsing methods to get an object representing the latest
news item in the data.
update: function(feedXml) {
var latest = this.getFirstItem(feedXml);
this.state = { };
this.state.latestData = latest;
this.state.timestamp = new Date();
localStorage['latestBrew'] = JSON.stringify(this.state);
this.renderLatest(latest);
},
The above code also shows the use of two important APIs that Chrome implements. The
localStorage is a way to persist information that lives in the client
machine and lasts even after the browser closes. We use it to remeber our last
results and avoid fetching and parsing the RSS each time the popup is opened.
The other API is the native JSON object that can replace any dedicated
library we are used to have in cross-browser websites. We need to stringify
the data because we can only save strings in the local storage.
With the parsed data at hand we just need to replace the content in those empty html tags in popup.html with the information we have.
Adding some life with events
The last piece of this puzzle are the jQuery event handlers that we created in the
init method. They make some of the elements clickable, including the
links, which open new tabs using chrome.tabs.create(). Also note starting on line
29 that if we find recent local data we use that instead of refreshing
the content from the RSS feed.
Let's load this thing up
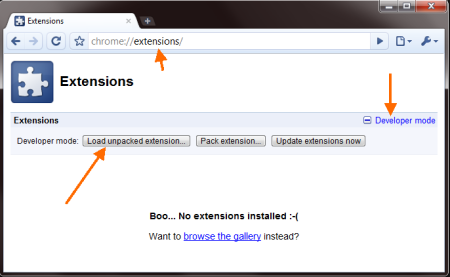
Now we just need to run it and see how it goes. Go to the extesions page, expand the Developer Mode area and click Load unpacked extension....
Then simply browse to your extension's directory and select it. The extension should now be listed as seen below.
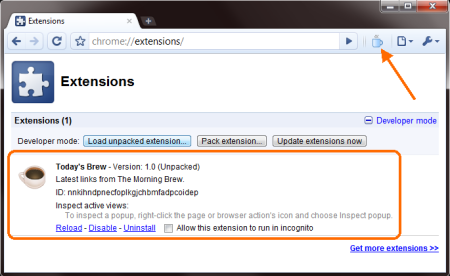
While you're developing your extension you can debug it using the developer tools included in Chrome. To do that, right click the extension button and select Inspect popup.
You can download the code for this extension and play with it all you want. I'm still early into learning this so feel free to give me pointers or ask questions.